The enterprise data stack has seen several waves of transformation over the years: from the “Hadoop era” and on-prem pipelines to the era of automated ETL pipelines that centralize the data in the warehouse, thereafter transforming it with the likes of dbt. The current era of transformation with newer data primitives like DuckDB and Iceberg is focused on enhancing openness, cost-effectiveness, access to compute and modularity. However, we believe that foundation models will help accelerate this transformation from the ground up by reshaping the daily routines of various data and ML practitioners.
As accessible Large Language Model (LLM) capabilities emerge, applications are poised to increasingly leverage a blend of classical ML and LLMs. Beyond streamlining tasks like code generation and automation of repetitive work, we anticipate LLMs reshaping how data and ML practitioners approach day-to-day activities. The emergence of a new application-building paradigm introduces roles like "AI engineer", which are redefining existing positions such as data engineering and application development. We delve into how this LLM wave influences the daily work of common data and ML practitioners.
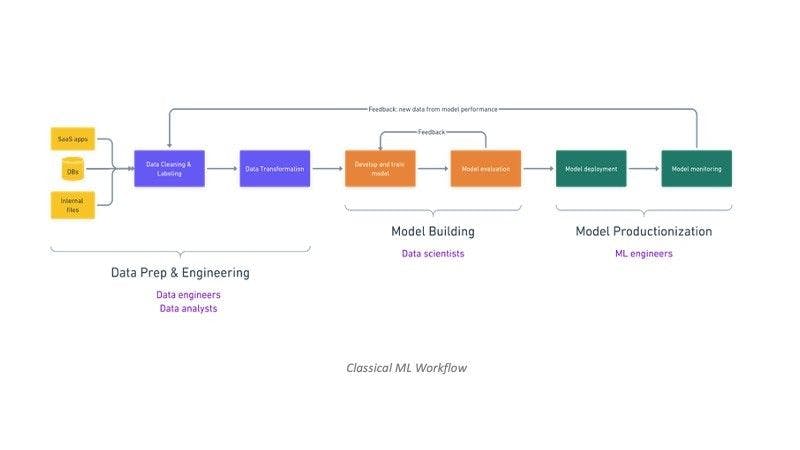
What is the classical ML workflow?
The classical machine learning (ML) workflow for building applications involves a series of steps. It begins with defining the problem and preparing relevant data. Feature engineering is performed to select and transform input data, followed by splitting the data into training, validation, and testing sets. A suitable ML model is chosen and trained on the training data, and hyper-parameters are tuned for optimal performance. Model evaluation is done on the validation set, and once satisfied, the model is deployed to a production environment. Continuous monitoring and maintenance are essential, along with scaling and optimization as needed. The model monitoring feedback is also fed into the initial phases of model building to catch data drift and other quality issues.
What is the LLM workflow?
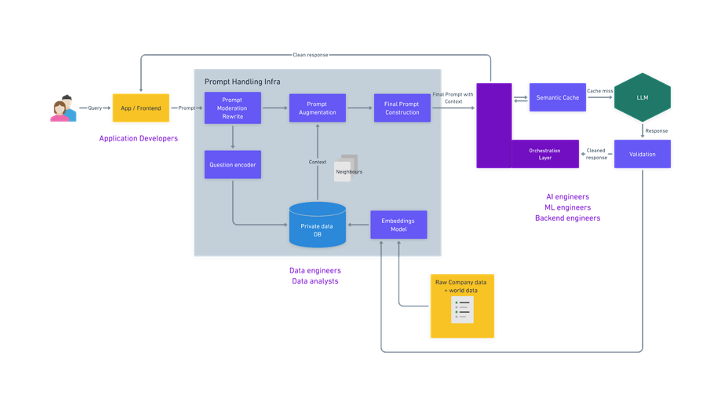
The classical ML workflow as defined, deals with training a model, while the LLM workflow as defined, deals with using a trained model in a real-time scenario. LLM capabilities are now generally accessible through pre-trained model REST API endpoints provided by Open AI, Anthropic et al. ML capabilities as an API are not a new thing, but the performance of these APIs on many tasks has significantly improved over the last couple of years, increasing their adoption, especially for organizations looking to catch up with the competition. These APIs empower developers and potentially less technical users, not only ML practitioners, to benefit from the unique capabilities of pre-trained models. While this workflow is still early, certain architectures like Retrieval augmented generation (RAG) are emerging to maintain freshness, provide context, and minimize hallucinations especially in specific tasks like Q&A and summarization.
Typical RAG architecture
How will LLMs (& AI agents) impact data and ML personas?
1. Just as in software development, co-pilot agents will make ML practitioners, data engineers and BI engineers 10X more effective
(i) Data-scientists & ML Engineers: Akin to productivity gains in code generation, classical ML models can now be built and deployed with fewer and less experienced data scientists and ML engineers:
- Rapid Prototyping: LLMs can accelerate the model prototyping phase by assisting in generating initial code and logic. Once the product teams describe the business problem, the LLM can suggest the steps, algorithms and architectures for specific tasks and objectives.
- Effective Feature engineering: LLMs can suggest features or transformations based on the context of the problem and the dataset. The existing feature engineering products and platforms focus on transforming, storing and serving features. With LLMs, data scientists can potentially extract the last mile of retrieving relevant features based on data and context.
- Triage model performance: LLMs can help with triaging model performance or drop-offs. With limited representative data, the model is unable to generalize unseen patterns. LLMs can help generate unseen patterns to triage model drop-offs, thereby making the feedback loop shorter.
(ii) Data Engineering: Data engineering workflows are known to be manual, requiring armies of engineers to deploy and maintain.
- Data integration workflows: Data integration is often hindered by variations in schemas and structures across data sources. LLMs can generate first pass transformation logic for mapping data between different schemas given source and target schema details. Additionally, diverse data formats (CSV, JSON, XML, etc.) complicate integration. LLMs can simplify this by producing code to convert data across formats. LLMs can also streamline the creation of ETL pipelines by generating workflow templates based on data integration descriptions.
- Data cleansing and prep: Data prep is one of the most cumbersome jobs for a data engineer where LLMs can help a ton. LLMs such as the ChatGPT code interpreter can suggest data cleansing techniques, identify outliers, and recommend methods for handling missing values (methods such as imputation, interpolation, or discarding incomplete records). Additionally, LLMs can suggest testing scenarios and generate test scripts for data pipelines, aiding in quality check and validation.
- Data orchestration frameworks: Data engineers can outline their intended workflow, and in response, LLMs can supply YAML or Python code templates to construct Airflow DAGs. Additionally, LLMs can generate task configurations, including identifiers, parameters, and interdependencies, all inferred from descriptions of requisites and connections. Data engineers can articulate their scheduling requirements, prompting LLMs to create code that dynamically arranges task schedules based on factors like data availability.
- Data labeling: Data labeling has traditionally been a manual process involving humans in the loop. This is one area where LLMs are deeply impactful in the more immediate term. Data labeled via an LLM can also be used to train smaller models. Most commercial models have licenses that don’t allow for labeling, but OSS models will likely change that.
(iii) BI Engineering: LLMs can empower analysts/BI engineers beyond simply being code assistants.
- Query optimization: LLMs can assist in optimizing SQL queries to reduce execution costs. By describing the data and query intent, data practitioners can receive suggestions for rewriting or optimizing queries. For example, LLMs can identify poor query patterns, provide recommendations for removing redundancy and identify the most effective query amongst multiple queries with different syntax, but similar intent.
- Complex data spelunking: LLMs can be great at data aggregation, identifying patterns and correlations, data disambiguation, assessing semantic similarity, and entity resolution.
2. Application Developers <> UX Designers, Application Developers <> DevOps and Application developers <> Data Engineers – the interfaces will shift as application developers develop capabilities to extend into their adjacencies
Application developers can harness the power of LLMs to develop capabilities that extend into their adjacencies. As a result, developers will be able to create simple applications that offer end-to-end automation of boilerplate tasks as well as agents to augment complex manual workflows. This category of applications will be less compute intensive and less dependent on UX designers, data engineers and devOps. Developers will take business objectives, specifics of the data sources and intended integrations, and LLMs can subsequently help:
- Implement UX: Frontend design systems typically involve repetitive manual work. LLMs can help in generating basic system components, UIs, create visualization components to add interactive charts, graphs, and visualizations to their applications. They can also potentially implement data binding to enable real-time updates of data driven UI elements. While LLMs can definitely help build the first version of the frontend and reduce the boilerplate code, intricate frontend systems will continue to require human intervention.
- Write basic micro-service architectures and integration tests: LLMs can help in generating basic micro-service architectures and write integration tests based on product objectives and application code. The needs across companies and teams are likely too nuanced for total automation, but it will be a powerful tool to boost developer productivity.
- Integrate with data-sources, APIs and LLMs: Given templates and constraints, LLMs can help in generating integration code for integrating with various data sources, APIs and services, as well as LLMs that help with summarization, content generation et al.
3. “Shift right” of applied AI has led to the emergence of a new persona - The AI Engineer
We are observing a once in a generation “shift right” of applied AI, fueled by the capabilities of foundation models and an API to interact with them. AI engineers aren’t researchers or data engineers. They’re responsible for working with LLMs that are few shot learners and exhibit in-context learning. These models have transfer capabilities that generalize beyond the original intent of model trainers and AI engineers are responsible for extracting that value for internal use cases. Given this focus, AI engineers will likely emerge from erstwhile ML engineers, app developers, or data scientists. Some of the core responsibilities of AI engineers include interacting with the exposed APIs of foundation models to achieve the expected performance level for an AI application. This new set of responsibilities can be greatly enhanced with LLMs.
- Building model validation systems: Engineering teams struggle with model reliability and ensuring implementations meet specifications. LLMs can aid in various steps of validating the output of models themselves. They can help in constructing the test data or validators that help in evals of the model responses.
- Unstructured data quality validation: Engineering teams are now being tasked to ensure data quality for input embeddings as well the quality of retrieved data. LLMs can help with data quality checks, identify missing data, and create resolution workflows, especially for RAG and fine-tuning.
- Optimization of models: AI engineers may also need to optimize code for efficiency, considering factors such as response time, resource utilization, and scalability. They may also be in charge of suggesting the right models to work with. Foundation models can be an aid for various such tasks including fine-tuning, and model optimization et al.
4. RevOps and FinanceOps teams will become autonomous and proactively data-driven
RevOps and FinanceOps have historically been dependent on data teams, and subsequently been reactive to data and insights. Today, LLMs can’t fully be trusted to write complex SQL queries and to write reliable transformations. However, today they provide a useful interface for users to interact with. Underneath that interface, data tools will need a lot of traditional application logic to make them useful. This doesn't mean that the status quo will be the future. Here are some of the capabilities that can be unlocked by LLMs in the medium to long term:
- Data Transformation: LLMs can potentially assist in generating reliable logic for data transformations, such as aggregations, joins, window functions, and pivots, based on descriptions of the desired outcomes. LLMs can suggest data modeling patterns, such as snowflake or star schemas, based on data engineer or analyst descriptions of the data structure. LLMs can also assist in generating SQL code for implementing data validation rules, and ensuring data quality.
- Business Insights in Q&A format: LLMs can potentially short circuit the whole data analysis workflow by simply answering the questions on unstructured and structured data. This enables data consumers to be way more productive, reducing the need to produce a SQL query, generate graphs and transform data.
We suspect the emergence of “AI engineers” and data scientists/engineers with LLM co-pilots will help address the unmet market need stemming from a scarcity of ML and data engineers. Overall, we envision that LLMs will meaningfully improve the productivity of different data workers by improving collaboration and productizing tasks that have historically been manual - not just those that are boilerplate, but especially those that require effort, domain knowledge and time. However, LLMs will not only provide copilots for a variety of tasks but also unlock some new capabilities: data spelunking (disambiguation, semantic similarity, entity resolution), unstructured data quality validation, and query optimization amongst many others.
Thanks to the brain trust, who provided feedback and contributed ideas, including Savin Goyal, Benn Stancil, Jordan Tigani, Diego Oppenheimer, Shreya Rajpal, Ashish Thusoo, Chad Sanderson, James Alcorn and Jocelyn Goldfein